 russ
russ从输入 URL 到页面加载
声明一下
此篇文档非原创,参考网上几篇文章和极客时间李兵老师的浏览器工作原理专栏写的。相当于学习笔记。
这个过程浏览器有三个进程一起完成的。分别是浏览器进程、网络进程、渲染进程。先来了解下它们的主要职责。
浏览器进程主要负责用户交互、子进程管理和文件储存等功能。
网络进程是面向渲染进程和浏览器进程等提供网络下载功能。
渲染进程的主要职责是把从网络下载的 HTML、JavaScript、CSS、图片等资源解析为可以显示和交互的页面。因为渲染进程所有的内容都是通过网络获取的,会存在一些恶意代码利用浏览器漏洞对系统进行攻击,所以运行在渲染进程里面的代码是不被信任的。
一、用户输入
当用户在浏览器地址栏中输入一个查询关键字时,浏览器会判断输入的关键字是搜索内容,还是请求的 URL。
如果是搜索内容,地址栏会使用浏览器默认的搜索引擎,来合成新的带搜索关键字的 URL。
如果判断输入内容符合 URL 规则,比如输入的是
wangzhihao.top,那么地址栏会根据规则,把这段内容加上协议,合成为完整的 URL,如https://wangzhihao.top。当浏览器刚开始加载一个地址之后,标签页上的图标便进入了加载状态。但此时页面显示的依然会是之前的页面内容,并没有立即替换为目标地址的页面。这是因为浏览器需要等待提交文档这个阶段之后,页面内容才会被替换。
二、URL 请求过程
在用户输入完成并按下回车键之后,浏览器就进入了页面资源的请求过程。这时候浏览器进程会通过进程间通信(IPC)将用户输入后产生的 URL 请求发送到网络进程,再由网络进程发起真正的 URL 请求流程。流程如下:
1、查找强缓存
- 网络进程会查找本地缓存中(强缓存)是否缓存了该资源。如果有缓存资源,那么直接返回资源给浏览器进程。
2、DNS 域名解析
- 如果在缓存中没有查找到资源,那么直接进入网络请求流程。这请求前的第一步是要进行 DNS 解析,以获取请求域名的服务器 IP 地址。如果请求协议是 HTTPS,那么还需要建立 TLS 连接。
什么是 DNS 域名解析?
- DNS(Domain Name System,域名系统),因特网上作为域名和 IP 地址相互映射的一个分布式数据库,能够使用户更方便的访问互联网,而不用去记住能够被机器直接读取的 IP 数串。通过主机名,最终得到该主机名对应的 IP 地址的过程叫做域名解析(或主机名解析)
DNS 查询的两种方式:递归查询和迭代查询
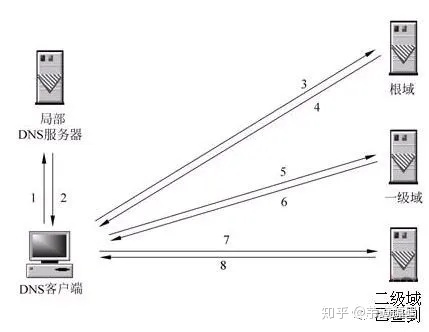
- 递归查询
当局部 DNS 服务器自己不能回答客户机的 DNS 查询时,它就需要向其他 DNS 服务器进行查询。此时有两种方式,如图所示的是递归方式。局部 DNS 服务器自己负责向其他 DNS 服务器进行查询,一般是先向该域名的根域服务器查询,再由根域名服务器一级级向下查询。最后得到的查询结果返回给局部 DNS 服务器,再由局部 DNS 服务器返回给客户端。

- 迭代查询
当局部 DNS 服务器自己不能回答客户机的 DNS 查询时,也可以通过迭代查询的方式进行解析,如图所示。局部 DNS 服务器不是自己向其他 DNS 服务器进行查询,而是把能解析该域名的其他 DNS 服务器的 IP 地址返回给客户端 DNS 程序,客户端 DNS 程序再继续向这些 DNS 服务器进行查询,直到得到查询结果为止。也就是说,迭代解析只是帮你找到相关的服务器而已,而不会帮你去查。比如说:http://baidu.com的服务器 ip 地址在 192.168.4.5 这里,你自己去查吧,本人比较忙,只能帮你到这里了。
3、建立连接
基于
DNS找到目标IP地址后,就是利用IP地址和服务器建立TCP连接。连接建立之后,浏览器端会构建请求行、请求头等信息,并把和该域名相关的Cookie等数据附加到请求头中,然后向服务器发送构建的请求信息。服务器接收到请求信息后,会根据请求信息生成响应数据(包括响应行、响应头和响应体等信息),并发给网络进程。等网络进程接收了响应行和响应头之后,就开始解析响应头的内容了。
重定向
在接收到服务器返回的响应头后,网络进程开始解析响应头,如果发现返回的状态码是 301 或者 302,那么说明服务器需要浏览器重定向到其他
URL。这时网络进程会从响应头的Location字段里面读取重定向的地址,然后再发起新的HTTP或者HTTPS请求,一切又重头开始了。在导航过程中,如果服务器响应行的状态码包含了 301、302 一类的跳转信息,浏览器会跳转到新的地址继续导航;如果响应行是 200,那么表示浏览器可以继续处理该请求。
响应数据类型处理
在处理了跳转信息之后,我们继续导航流程的分析。
URL请求的数据类型,有时候是一个下载类型,有时候是正常的HTML页面,那么浏览器是如何区分它们呢?答案是
Content-Type。Content-Type 是HTTP头中一个非常重要的字段, 它告诉浏览器服务器返回的响应体数据是什么类型,然后浏览器会根据Content-Type的值来决定如何显示响应体的内容。如果响应头中的 Content-type 字段的值是
text/html,这就是告诉浏览器,服务器返回的数据是HTML格式。如果Content-Type的值是application/octet-stream,显示数据是字节流类型的,通常情况下,浏览器会按照下载类型来处理该请求。不同
Content-Type的后续处理流程也截然不同。如果Content-Type字段的值被浏览器判断为下载类型,那么该请求会被提交给浏览器的下载管理器,同时该URL请求的导航流程就此结束。但如果是 HTML,那么浏览器则会继续进行导航流程。由于Chrome的页面渲染是运行在渲染进程中的,所以接下来就需要准备渲染进程了。
三、准备渲染进程
默认情况下,
Chrome会为每个页面分配一个渲染进程,也就是说,每打开一个新页面就会配套创建一个新的渲染进程。但是,如果多个页面属于同一站点的话,浏览器会让多个页面直接运行在同一个渲染进程中。“同一站点”定义为根域名(例如,wangzhihao.top)加上协议(例如,https:// 或者 http://),还包含了该根域名下的所有子域名和不同的端口,比如下面这三个:
https://blog.wangzhihao.top
https://www.wangzhihao.top
https://www.wangzhihao.top:8080它们都是属于同一站点,因为它们的协议都是 HTTPS,而且根域名也都是 wangzhihao.top。
Chrome的默认策略是,每个标签对应一个渲染进程。但如果从一个页面打开了另一个新页面,而新页面和当前页面属于同一站点的话,那么新页面会复用父页面的渲染进程。官方把这个默认策略叫process-per-site-instance。渲染进程准备好之后,还不能立即进入文档解析状态,因为此时的文档数据还在网络进程中,并没有提交给渲染进程,所以下一步就进入了提交文档阶段。
四、提交文档
首先要明确一点,这里的“文档”是指 URL 请求的响应体数据。
“提交文档”的消息是由浏览器进程发出的,渲染进程接收到“提交文档”的消息后,会和网络进程建立传输数据的“管道”。
等文档数据传输完成之后,渲染进程会返回“确认提交”的消息给浏览器进程。
浏览器进程在收到“确认提交”的消息后,会更新浏览器界面状态,包括了安全状态、地址栏的 URL、前进后退的历史状态,并更新
Web页面。这也就解释了为什么在浏览器的地址栏里面输入了一个地址后,之前的页面没有立马消失,而是要加载一会儿才会更新页面。
到这里,一个完整的导航流程就“走”完了,这之后就要进入渲染阶段了。
五、渲染过程
由于渲染机制过于复杂,所以渲染模块在执行过程中会被划分为很多子阶段,输入的 HTML 经过这些子阶段,最后输出像素。我们把这样的一个处理流程叫做渲染流水线,其大致流程如下图所示:
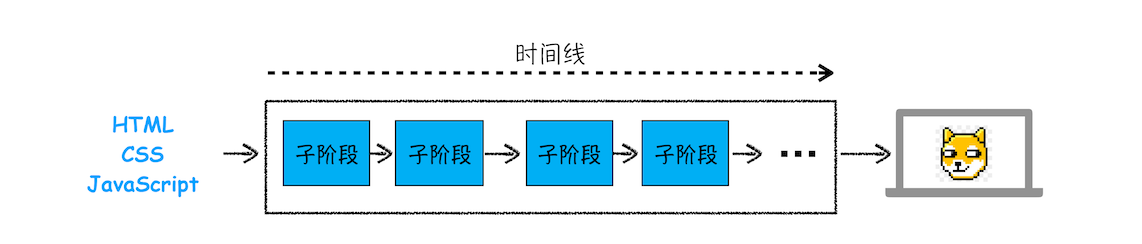
按照渲染的时间顺序,流水线可分为如下几个子阶段:
- 构建 DOM 树。
- 样式计算。
- 布局阶段。
- 分层。
- 绘制。
- 分块。
- 光栅化。
- 合成。
现在就开始一个一个阶段分析吧。
开始每个子阶段都有其输入的内容。
然后每个子阶段有其处理过程。
最终每个子阶段会生成输出内容。
1、构建 DOM 树(HTML 文件 -> DOM 树)
为什么要构建
DOM树呢?这是因为浏览器无法直接理解和使用HTML,所以需要将HTML转换为浏览器能够理解的结构——DOM树。构建
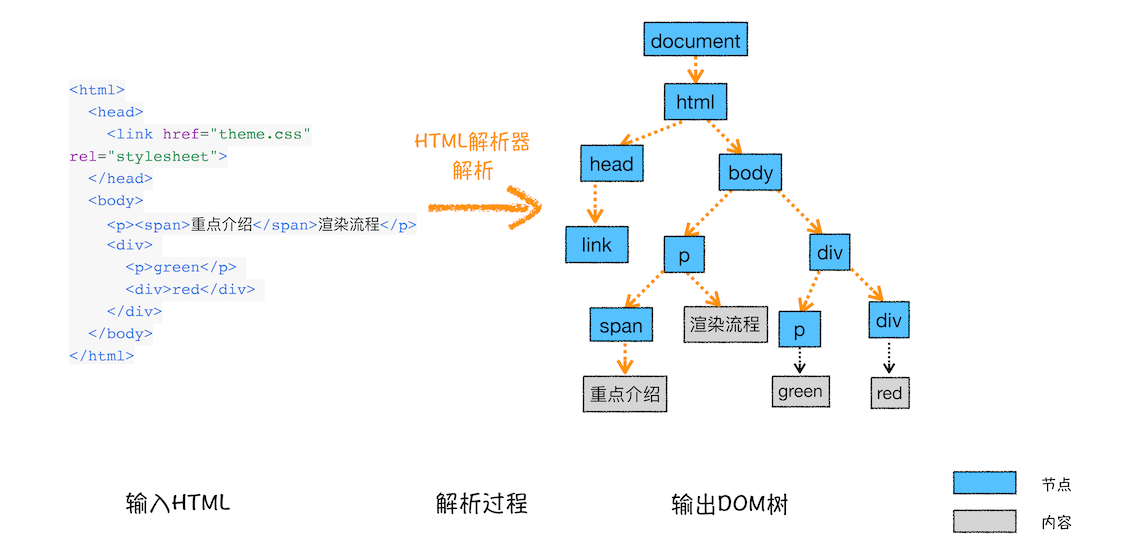
DOM树的过程如下图。
构建
DOM树得输入内容是一个非常简单的HTML文件,然后经由HTML解析器解析之后输出树状结构的DOM,即DOM树。DOM 和 HTML 内容几乎是一样的,但是。
DOM 树解析的过程是一个深度优先遍历。即先构建当前节点的所有子节点,再构建下一个兄弟节点。
在读取 HTML 文档,构建 DOM 树的过程中,若遇到 script 标签,则 DOM 树的构建会暂停,直至脚本执行完毕。
这一步我们用网络进程提供的 HTML 文件经过 HTML 解析器解析之后我们得到了 DOM 树。但是 DOM 节点的样式我们依然不知道,所以接下来就需要样式计算了。
2、样式计算(css 文本 -> ComputedStyle)
样式计算的目的是为了计算出 DOM 节点中每个元素的具体样式,这个阶段大体可分为三步来完成。
第一步——把 CSS 转换为浏览器能够理解的结构
CSS 样式来源主要有三种:
- 通过
link引用的外部CSS文件 - style 标签内的
CSS - 元素的
style属性内嵌的CSS
和 HTML 文件一样,浏览器也是无法直接理解这些纯文本的 CSS 样式,所以当渲染引擎接收到 CSS 文本时,会执行一个转换操作,将 CSS 文本转换为浏览器可以理解的结构——styleSheets。转换出来的 styleSheets 同时具备了查询和修改功能,这会为后面的样式操作提供基础。
第二步——将样式表中的属性值标椎化
要理解什么是属性值标准化,你可以看下面这样一段 CSS 文本:
body { font-size: 2em }
p {color:blue;}
span {display: none}
div {font-weight: bold}
div p {color:green;}
div {color:red; }可以看到上面的 css 文本中有很多属性值,如 2em、blue、bold,这些类型数值不容易被渲染引擎理解,所以需要将所有值转换为渲染引擎容易理解的、标准化的计算值,这个过程就是属性值标准化。
标椎化后的属性值如图所示:
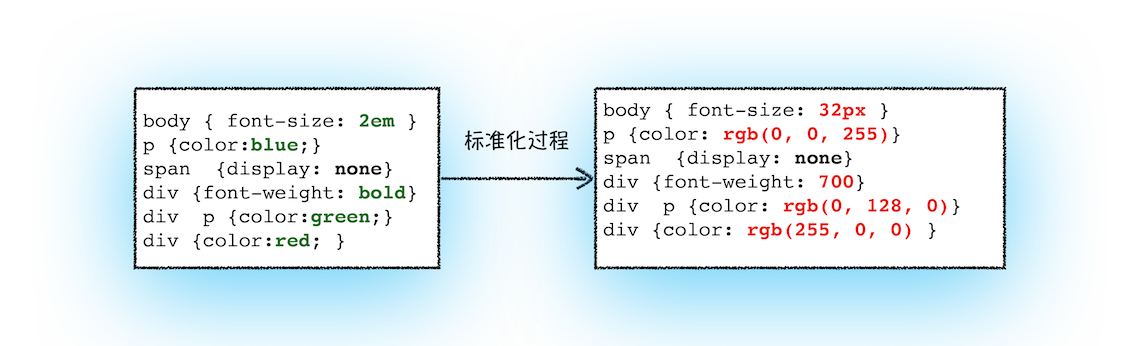
从图中可以看到,2em 被解析成了 32px,red 被解析成了 rgb(255,0,0),bold 被解析成了 700。
第三步——计算出 DOM 树中每个节点的具体样式
- 通过 css 的继承规则和层叠规则计算出每个节点的样式具体值。
- CSS 继承就是每个 DOM 节点都包含有父节点的样式。
- 层叠是 CSS 的一个基本特征,它是一个定义了如何合并来自多个源的属性值的算法。它在 CSS 处于核心地位,CSS 的全称“层叠样式表”正是强调了这一点。
- 这个阶段最终输出的内容是每个 DOM 节点的样式,并被保存在 ComputedStyle 的结构内。
3、布局阶段(DOM 树 + CSS 样式表 -> 布局树)
现在,我们有 DOM 树和 DOM 树中元素的样式,但这还不足以显示页面,因为我们还不知道 DOM 元素的几何位置信息。那么接下来就需要计算出 DOM 树中可见元素的几何位置,我们把这个计算过程叫做布局。
Chrome 在布局阶段需要完成两个任务:创建布局树和布局计算。
第一步——创建布局树
因为 DOM 树包含了很多不需要在页面上展示的元素,比如 head 标签,还有使用了 css 样式 display: none 的元素。所以在渲染页面之前,还需要构建一颗只包含可见元素的布局树 🌲。大致流程有一下两步:
- 1、遍历 DOM 树中的所有可见节点,并把这些节点加到布局中。
- 而不可见的节点会被丢掉,比如上面说的 head 标签下的全部内容,还有属性包含 display: none 的节点。
第二步——布局计算
现在我们有了一棵完整的布局树。那么接下来,就要计算布局树节点的坐标位置了。
在执行布局操作的时候,会把布局运算的结果重新写回布局树中,所以布局树既是输入内容也是输出内容,这是布局阶段一个不合理的地方,因为在布局阶段并没有清晰地将输入内容和输出内容区分开来。针对这个问题,Chrome 团队正在重构布局代码,下一代布局系统叫 LayoutNG,试图更清晰地分离输入和输出,从而让新设计的布局算法更加简单。
4、分层(布局树 -> 图层树)
我们有了布局树,而且每个元素的具体位置信息都计算出来了,那么接下来是不是就要开始着手绘制页面了?答案依然是否定的。
因为页面中有很多复杂的效果,如一些复杂的 3D 变换、页面滚动,或者使用 z-indexing 做 z 轴排序等,为了更加方便地实现这些效果,渲染引擎还需要为特定的节点生成专用的图层,并生成一棵对应的图层树(LayerTree)。
并不是布局树的每个节点都包含一个图层,如果一个节点没有对应的层,那么这个节点就从属于父节点的图层。
瞒足以下两点中的任意一点的元素就会被浏览器提升为单独的一层。
1、拥有层叠上下文属性的元素。
2、需要剪裁(clip)的地方也会被创建为图层。(比如 div 大小写死了,里面的内容超出了父元素的大小。出现了滚动条也是单独的图层。)
5、图层绘制(图层树 -> 待绘制列表)
在完成图层树的构建之后,渲染引擎会对图层树中的每个图层进行绘制。
渲染引擎实现图层的绘制会把一个图层的绘制拆分成很多小的绘制指令,然后再把这些指令按照顺序组成一个待绘制列表。
6、图层分块
因为用户正常情况下看到的东西只是屏幕的大小(视口)。所以刚开始没有必要绘制出图层的所有内容。
基于这个原因,合成线程会将图层划分为图块(tile),这些图块的大小通常是 256x256 或者 512x512。
然后合成线程会按照视口附近的图块来优先生成位图,实际生成位图的操作是由栅格化来执行的。所谓栅格化,是指将图块转换为位图。而图块是栅格化执行的最小单位。渲染进程维护了一个栅格化的线程池,所有的图块栅格化都是在线程池内执行的。
7、光栅化
通常,栅格化过程都会使用 GPU 来加速生成,使用 GPU 生成位图的过程叫快速栅格化,或者 GPU 栅格化,生成的位图被保存在 GPU 内存中。
GPU 操作是运行在 GPU 进程中,如果栅格化操作使用了 GPU,那么最终生成位图的操作是在 GPU 中完成的,这就涉及到了跨进程操作(IPC)。
8、合成与显示
一旦所有图块都被光栅化,合成线程就会生成一个绘制图块的命令——“DrawQuad”,然后将该命令提交给浏览器进程。
浏览器进程里面有一个叫 viz 的组件,用来接收合成线程发过来的 DrawQuad 命令,然后根据 DrawQuad 命令,将其页面内容绘制到内存中,最后再将内存显示在屏幕上。
到这里,经过这一系列的阶段,编写好的 HTML、CSS、JavaScript 等文件,经过浏览器就会显示出漂亮的页面了。
渲染流程总结
1、渲染进程用 HTML 解析器将 HTML 文本内容解析为 DOM 树 🌲。
2、渲染引擎将 CSS 样式表转换为浏览器可以理解的 styleSheets,计算出 DOM 节点的样式。
3、创建布局树,并计算元素的布局信息。
4、对布局树进行分层,得到图层树。
5、为每个图层生成绘制列表,并提交给合成线程。
6、合成线程将图层分为图块,并在光栅化线程池中将图块转换成位图。
7、合成线程发送绘制图块命令 DrawQuad 给浏览器。
8、浏览器进程根据 DrawQuad 消息生成页面,并显示到页面上。